FaceFusion 是一个开源的、业界领先的人脸操作平台,支持换脸、画质增强、唇形同步等功能。基于 Python + ONNX Runtime,提供 GPU 加速推理,同时提供 Web UI 交互界面和 headless 命令行模式。
一、FaceFusion 是什么 链接到标题
FaceFusion 是一个开源的、业界领先的人脸操作平台,支持换脸、画质增强、唇形同步等功能。基于 Python + ONNX Runtime,提供 GPU 加速推理,同时提供 Web UI 交互界面和 headless 命令行模式。
相比其他换脸方案:
- 相比 DeepFaceLab / Roop:FaceFusion 开箱即用,不需要复杂训练
- 相比 Stable Diffusion 换脸(ReActor/IP-Adapter):FaceFusion 速度快得多,但不依赖扩散模型,效果各有优劣
二、基于 Docker Compose 安装 链接到标题
2.1 部署配置 链接到标题
services:
facefusion:
image: docker.m.daocloud.io/facefusion/facefusion:3.6.1-cuda
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
ports:
- "7860:7860"
volumes:
- /mnt/data/facefusion/models:/facefusion/.assets/models
command: python /facefusion/facefusion.py run --face-detector-model retinaface \
--frame-enhancer-model real_hatgan_x4 \
--lip-syncer-model edtalk_256
关键说明:
--gpus:需要 NVIDIA GPU,建议显存 8GB 以上- 模型目录用 volume 持久化,避免每次启动重新下载
command参数指定使用最强模型组合(后面详述)
2.2 模型下载——最大的坑 链接到标题
FaceFusion 首次启动时会自动下载所需的 ONNX 模型文件,每个几十到几百 MB 不等。GitHub 国内下载速度极慢,实测经常掉到 50-200 kB/s,一个 258MB 的模型可能下半小时。
解决经验:
- 持久化模型目录:上面配置中的
volumes将模型缓存到宿主机,重启容器不需要重下 - 预下载全部模型:
docker exec facefusion-container python /facefusion/facefusion.py force-download --download-scope full - 续传大文件:下载慢时用 curl 续传:
curl -C - -o edtalk_256.onnx \ https://github.com/facefusion/facefusion-assets/releases/download/models-3.3.0/edtalk_256.onnx - 耐心!全部模型约 3.6GB,网络不好建议放后台慢慢下
2.3 Web UI 使用 链接到标题
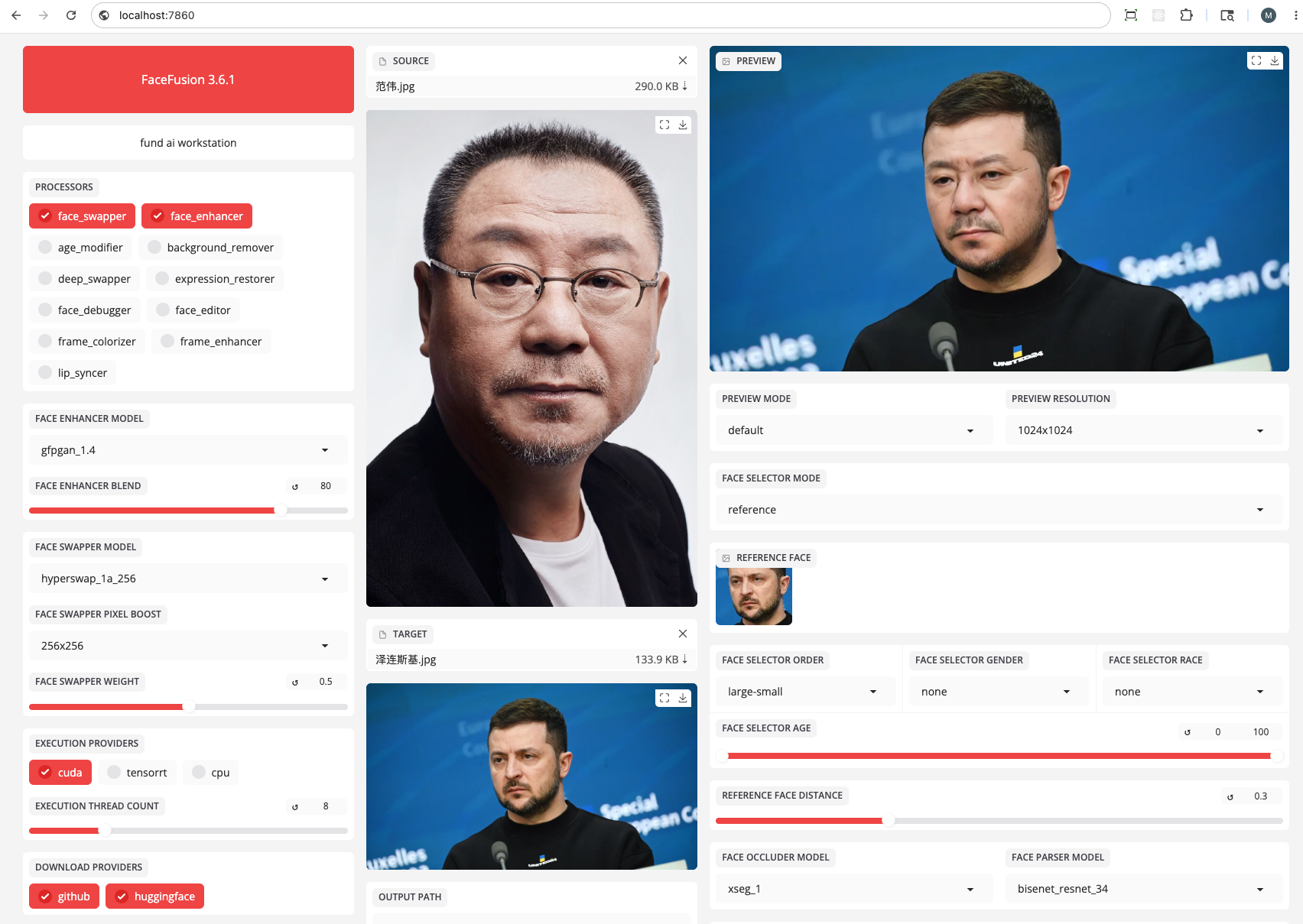
启动后浏览器访问 http://localhost:7860。
基本流程:
- 左边 Source 面板上传源人脸图片(要被换掉的脸)
- 右边 Target 面板上传目标图片或视频(要被换上去的脸)
- 点击下方处理按钮,等待输出
注意:如果拖入视频但只输出了一张图片,检查右侧 Output 设置——Output Video Encoder 要选择一个编码器(如 libx264),否则默认输出静态图片。
三、Docker CLI 命令行模式 链接到标题
FaceFusion 提供了 headless-run 子命令,可以直接在终端中处理图片和视频,不需要打开浏览器。这个模式非常适合集成到脚本和自动化工作流中。
3.1 图片换脸 链接到标题
docker run --rm --gpus all \
-v /mnt/data/facefusion/models:/facefusion/.assets/models \
-v $(pwd):/work \
docker.m.daocloud.io/facefusion/facefusion:3.6.1-cuda \
python /facefusion/facefusion.py headless-run \
-s /work/source.jpg \
-t /work/target.jpg \
-o /work/output.jpg \
--processors face_swapper \
--face-swapper-model hyperswap_1a_256
-s:源人脸图片-t:目标图片/视频-o:输出路径--processors:启用哪些处理器,多个以空格分隔--rm:容器用完自动删除,不留残
3.2 视频换脸 链接到标题
视频换脸与图片换脸命令完全一致,FaceFusion 自动识别输入是图片还是视频:
docker run --rm --gpus all \
-v /mnt/data/facefusion/models:/facefusion/.assets/models \
-v $(pwd):/work \
docker.m.daocloud.io/facefusion/facefusion:3.6.1-cuda \
python /facefusion/facefusion.py headless-run \
-s /work/source.jpg \
-t /work/target_video.mp4 \
-o /work/output_video.mp4 \
--processors face_swapper \
--face-swapper-model hyperswap_1a_256
实测数据:2796 帧,1080×720@30fps,耗时 2 分 41 秒,处理速度约 155 frame/s。原始视频 16MB,输出 50MB(默认 libx264 编码)。
额外参数:
--output-video-encoder libx265:改用 H.265 编码,体积更小--output-video-quality 80:调节输出质量(0-100)--trim-frame-start / --trim-frame-end:裁剪视频片段
3.3 批量处理 链接到标题
docker run --rm --gpus all \
-v /mnt/data/facefusion/models:/facefusion/.assets/models \
-v $(pwd):/work \
docker.m.daocloud.io/facefusion/facefusion:3.6.1-cuda \
python /facefusion/facefusion.py batch-run \
-s "/work/faces/*.jpg" \
-t "/work/targets/*.mp4" \
-o "/work/output/{name}-{transformed}.mp4" \
--processors face_swapper \
--face-swapper-model hyperswap_1a_256
batch-run 支持 glob 模式匹配,自动组合源和目标的笛卡尔积。
四、Windmill 脚本集成 链接到标题
FaceFusion 通过 docker run --gpus all 方式调用,天然适合接入 Windmill 工作流。
4.1 前置条件 链接到标题
Windmill 需要配置 GPU Worker:
# docker-compose.yml 中的 worker 配置
windmill_worker_gpu:
image: ghcr.io/windmill-labs/windmill:latest
environment:
- MODE=worker
- WORKER_GROUP=gpu
- WORKER_TAGS=gpu
volumes:
- /var/run/docker.sock:/var/run/docker.sock
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
关键点:
- 挂载 Docker socket(
/var/run/docker.sock),让 worker 内部可以执行docker run - Worker 打上
gputag - 在 Windmill 中创建脚本时设置
tag: gpu,确保调度到 GPU worker
4.2 Python 脚本示例 链接到标题
import subprocess
import json
def main(source_path: str, target_path: str, output_path: str,
face_swapper: str = "hyperswap_1a_256",
face_enhancer: str = "gfpgan_1.4"):
cmd = [
"docker", "run", "--rm", "--gpus", "all",
"-v", "/mnt/data/facefusion/models:/facefusion/.assets/models",
"-v", f"/tmp/facefusion/input:/input",
"-v", f"/tmp/facefusion/output:/output",
"docker.m.daocloud.io/facefusion/facefusion:3.6.1-cuda",
"python", "/facefusion/facefusion.py", "headless-run",
"-s", f"/input/{source_path}",
"-t", f"/input/{target_path}",
"-o", f"/output/{output_path}",
"--processors", "face_swapper",
"--face-swapper-model", face_swapper,
]
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode != 0:
raise Exception(f"FaceFusion failed: {result.stderr}")
return {"output": output_path, "duration": "ok"}
4.3 Bash 脚本示例 链接到标题
docker run --rm --gpus all \
-v /mnt/data/facefusion/models:/facefusion/.assets/models \
-v "$WDIR":/work \
docker.m.daocloud.io/facefusion/facefusion:3.6.1-cuda \
python /facefusion/facefusion.py headless-run \
-s "/work/${SOURCE}" -t "/work/${TARGET}" -o "/work/${OUTPUT}" \
--processors face_swapper --face-swapper-model hyperswap_1a_256
echo "{\"output\": \"$OUTPUT\"}"
五、推荐模型组合 链接到标题
FaceFusion 3.6.1 内置多种模型,以下是经过实测的最佳组合:
| 处理器 | 推荐模型 | 说明 |
|---|---|---|
| 换脸 | hyperswap_1a_256 |
FaceFusion 2025 年自研模型,13 个换脸模型中质量最高 |
| 人脸画质增强 | gfpgan_1.4 |
GFPGAN 最新版,修复面部细节效果自然 |
| 帧画质增强 | real_hatgan_x4 |
GAN 架构 4 倍超分,效果显著优于默认的 span_kendata_x4 |
| 唇形同步 | edtalk_256 |
256p 分辨率,远超 wav2lip_gan_96 的 96p |
| 人脸检测 | retinaface |
InsightFace 检测器,比默认的 yoloface 更精确 |
启动时通过 command 参数指定:
command: python /facefusion/facefusion.py run \
--face-detector-model retinaface \
--frame-enhancer-model real_hatgan_x4 \
--lip-syncer-model edtalk_256
headless 模式同理加上对应参数即可。
六、效果评价与经验总结 链接到标题
图片换脸——效果一般 ⭐⭐ 链接到标题

猜猜像谁:
- kimi:先猜沈腾,再猜是沙溢
- grok:黄渤
- 智谱:沈逸
其实是:范伟 😓
基于 hyperswap_1a_256 的图片换脸,在光影、角度差异较大的两张照片之间,效果不够自然:
- 肤色、光照不匹配时,融合边界明显
- 更适合证件照、光影接近的两张图
- 不如扩散模型方案(Stable Diffusion + IP-Adapter / ReActor)自然
原因分析:FaceFusion 的换脸模型本质是 autoencoder 架构(隐空间编码-解码),对光影和角度变化的泛化能力有限。而扩散模型通过去噪过程逐步生成,天然能更好地处理光照和姿态变化。
视频换脸——效果不错 ⭐⭐⭐⭐ 链接到标题
但同样的模型、同样的参数,换到视频上效果明显更好,看起来挺自然。

这是我口播视频换脸,效果好行吧。😌
为什么视频反而比图片好?
- 视觉暂留效应——人眼对运动画面中的细节不敏感,帧间的瑕疵被快速运动掩盖过去了
- 帧间连续性——相邻帧变化很小,过渡自然,不会像单张图片那样被盯住看
- 视频编码的"美化"效果——libx264 压缩会抹掉高频噪声,反而让结果更柔和
- 而静态图片上,用户有充足时间盯着每一个像素看,任何不自然的边缘或融合痕迹都会被放大
结论 链接到标题
| 场景 | 推荐方案 |
|---|---|
| 需要高精度单图换脸 | Stable Diffusion(ReActor / IP-Adapter) |
| 视频换脸、批量处理、自动化 | FaceFusion + headless,务实且高效 |
FaceFusion 的优势不在于静态图片的精度,而在于速度(不用跑扩散)、视频处理能力强、可脚本化。视频换脸场景下,它是最省心的选择。